CLIP(Contrastive Language-Image Pre-training)模型,是OpenAI开发的一种多模态大模型。该模型通过对比学习的方式,在大规模图像-文本对上进行预训练,成功实现了图像和文本信息的跨模态对齐。CLIP模型的关键在于其采用了双塔结构,分别处理图像和文本数据,并通过对比损失函数进行优化,从而在图像和文本之间建立起紧密的联系。
在技术细节上,CLIP模型的图像编码器可以采用多种结构,如ResNet、Vision Transformer等,用于从图像中提取特征信息。文本编码器则通常采用Transformer结构,处理文本数据并生成文本特征。在训练过程中,模型通过对比图像和文本之间的相似性,学习将相似的图像和文本映射到相近的特征空间。这种学习方式使CLIP模型在处理多模态数据时具有出色的性能。
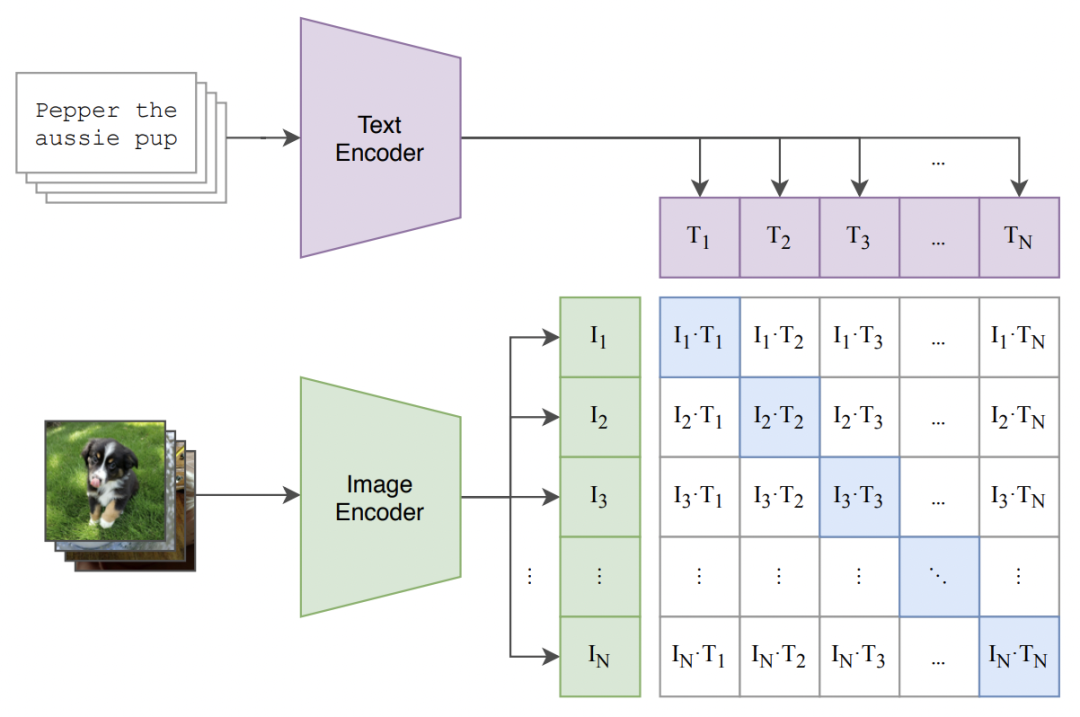
CLIP多模态大模型的核心优势
CLIP(Contrastive Language-Image Pre-training)是OpenAI开发的一种革命性多模态模型,通过对比学习方式在大规模图像-文本对上进行预训练,实现了图像和文本信息的跨模态对齐。其主要优势包括:
强大的跨模态对齐能力:CLIP采用双塔结构(图像编码器和文本编码器),通过对比损失函数优化,将图像和文本映射到共享的语义空间,使相似内容在特征空间中接近。这种设计使其能够理解图像和文本之间的深层语义关系。
卓越的零样本学习能力:CLIP无需针对特定任务进行微调,仅通过文本提示(prompt)就能完成多种视觉任务,如图像分类、检索等。研究表明,CLIP的zero-shot性能总体上比传统监督学习方法(如ResNet-50)更好。
高效的迁移学习特性:CLIP预训练后可以轻松迁移到各种下游任务,包括图像生成(如Stable Diffusion)、视觉问答、图文检索等。这种特性大大降低了特定任务的数据标注需求。
大规模预训练带来的泛化能力:原始CLIP模型使用4亿对图像-文本数据进行训练,使其学习到了广泛的视觉概念和语言关联。后续改进版本如EVA-CLIP-18B参数规模达到180亿,在27个图像分类基准上取得了80.7%的零样本准确率。
灵活的双塔架构:图像和文本特征可以预先计算并独立存储,特别适合检索类任务。这种设计也便于模型在不同场景下的部署和优化。
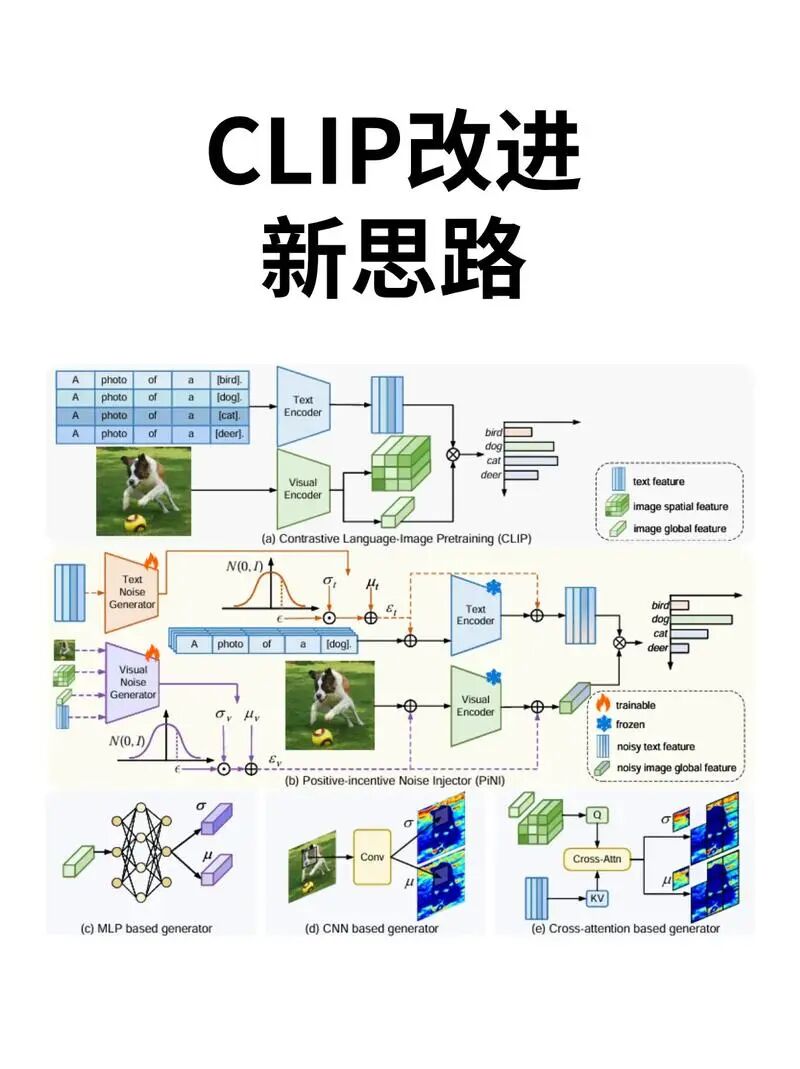
CLIP在边缘计算中的应用主要体现在提高人脸识别准确率和应用效能方面。结合 Transformer 、CLIP与 边缘计算 ,可以在多样化场景下(如低光照、姿态变化、表情多样性等)显著提高系统的鲁棒性和效率。Transformer架构能够有效捕捉图像中长距离像素之间的依赖关系,提升复杂场景下的识别精度,而边缘计算则通过在设备端处理数据,减少数据传输和云端处理负担,从而提高响应速度和降低延迟。具体应用场景包括智能监控与安防、智能门禁与身份认证以及移动端应用等。
CLIP模型应用实战
CLIP模型在图像检索与分类任务中具有显著的优势。通过输入文本描述,模型可以在大量图像中快速找到与描述相符的图像。这种能力使得CLIP模型在商品搜索、广告设计等领域具有广泛的应用前景。此外,CLIP模型还可以用于图像分类任务,通过对图像进行特征提取和相似度计算,实现自动化的图像分类。
基于CLIP模型的文本生成图像技术已成为创意设计领域的新热点。通过输入一段文本描述,模型可以生成与之相符的图像作品。这种技术为设计师提供了一种全新的创作方式,大大提高了创意设计的效率和质量。
CLIP模型在跨模态理解与交互方面也具有重要意义。在智能问答、机器人交互等场景中,CLIP模型可以帮助机器更好地理解用户的意图和需求。例如,在智能家居场景中,用户可以通过语音或文本指令控制家用电器,CLIP模型则负责解析指令并与相应的设备进行交互。这种跨模态理解能力使得人机交互更加自然和便捷。
CLIP作为边缘多模态模型的优势
将CLIP类多模态大模型部署到边缘设备具有以下显著优势:
实时响应能力:边缘部署避免了将数据传输至云端处理的延迟,对于智能监控、工业检测等实时性要求高的场景至关重要。实验显示,优化后的边缘视觉应用可实现48.2FPS的处理速度,性能提升2.4倍。
数据隐私保护:敏感视觉数据(如人脸、医疗影像)在本地处理,无需上传云端,降低了隐私泄露风险。这一特性在医疗、金融等对数据安全要求高的领域尤为重要。
带宽和成本节约:边缘计算减少了大量原始数据的上传需求,仅需传输处理后的结果或特征向量,显著降低了网络带宽消耗和云服务成本。
离线工作能力:边缘设备可在网络连接不稳定或完全离线的环境下正常工作,提高了系统的可靠性和可用性。
分布式计算潜力:多个边缘节点可以协同工作,共同完成复杂的多模态分析任务,形成分布式智能网络。
边缘部署中的参数与性能优化策略
为了在资源受限的边缘设备上高效运行CLIP类多模态大模型,需要采用多种优化策略:
模型压缩技术:
量化:将模型参数从FP32转换为INT8或更低精度,减少存储和计算需求。如TensorRT量化可使推理速度提升43%。
剪枝:移除模型中冗余的连接或神经元,降低模型复杂度。
知识蒸馏:使用大型CLIP模型(教师)训练小型化学生模型,保持性能的同时减少参数量。
硬件加速:
计算流程优化:
模型架构适配:
边缘-云协同:
将基础特征提取放在边缘,复杂分析任务卸载到云端。
实施模型分片,将不同层部署在不同计算节点上。
典型边缘部署性能指标
根据实际部署案例,优化后的CLIP类模型在边缘设备上可达到以下性能水平:
NVIDIA Jetson AGX Xavier设备:
通用边缘服务器:
模型大小与精度权衡:
应用场景与未来方向
CLIP多模态模型在边缘计算环境中的典型应用包括:
智能监控与安防:实时人脸识别、异常行为检测
工业视觉检测:产品质量自动检验、缺陷识别
智能零售:商品识别、顾客行为分析
医疗边缘计算:医学影像初步分析、远程诊断辅助
自动驾驶:实时环境感知与理解
未来发展方向包括:
CLIP类多模态大模型与边缘计算的结合,正在开启"无处不在的多模态智能"新时代,将为各行业带来更智能、更隐私安全、更实时的AI应用体验。







