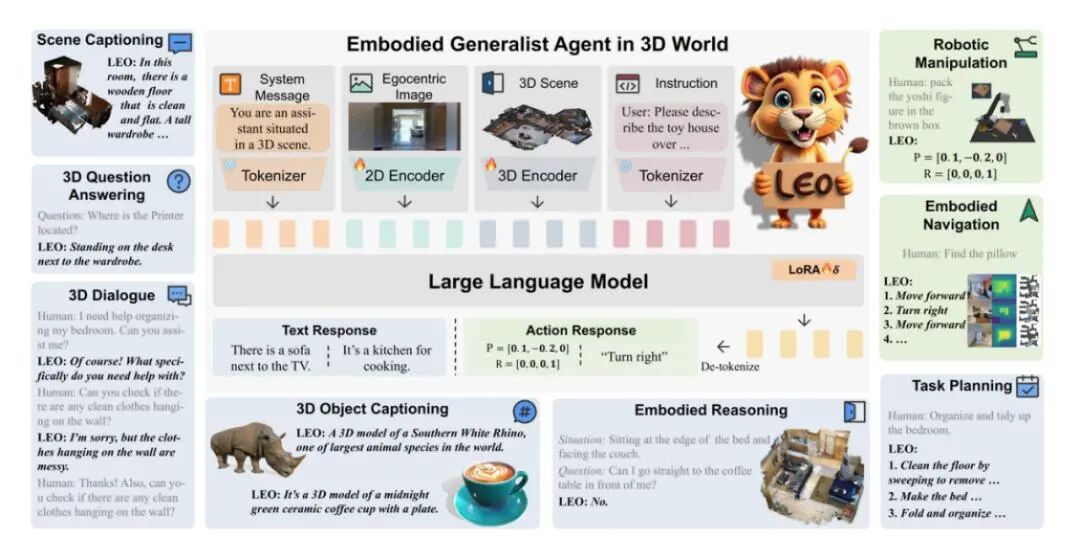
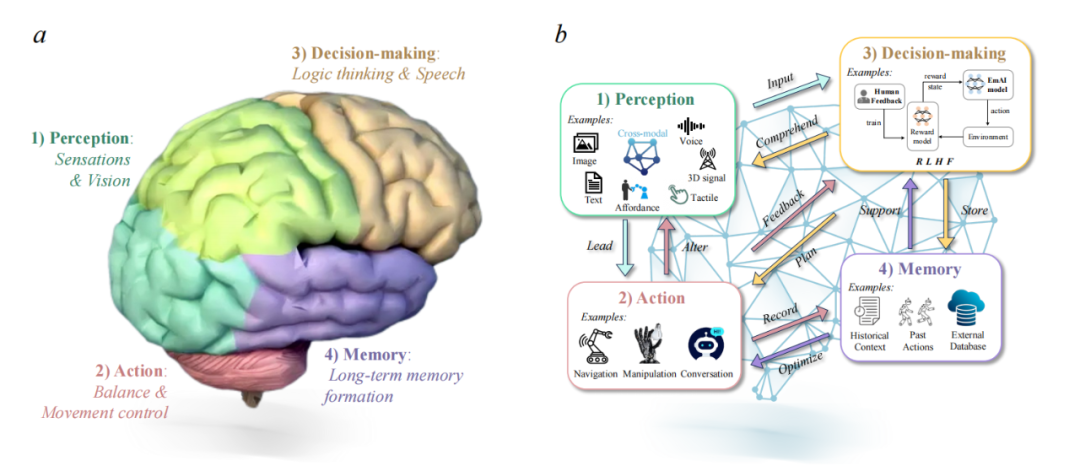
具身智能机器人是链接虚拟数字世界和现实物理世界的最佳载体,是虚实融合的理想产物,其性能表现也高度依赖于软件与硬件的全方位进化。
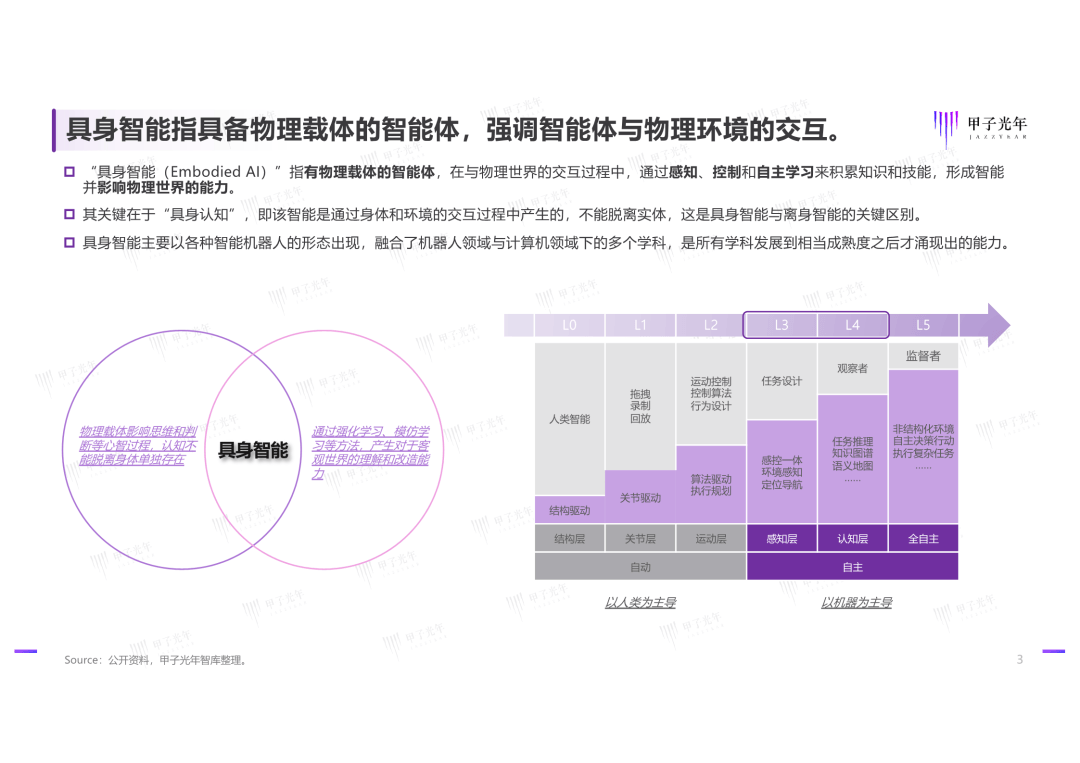
具身智能多模态大模型代表了人工智能领域的最新发展方向,它将大语言模型的认知能力与物理世界的交互能力相结合,为机器人、自动驾驶、医疗健康等领域带来了革命性的变革。以下从核心技术、典型模型、应用场景和发展挑战四个方面进行全面分析。
核心技术架构
具身智能多模态大模型的核心在于实现感知、推理、规划与执行的无缝衔接,其技术架构通常包含以下关键组件:
多模态感知融合
分层决策系统
三维时空建模
记忆与学习机制
典型模型与突破
近年来,全球研究机构陆续推出了一系列具身智能多模态大模型,各具特色:
LEO (北京通用人工智能研究院)
首个精通3D任务的具身通才智能体,基于Vicuna-7B构建,通过两阶段训练(3D视觉-语言对齐、视觉-语言-动作微调)实现
在ScanQA问答、Scan2Cap描述、SQA3D推理等任务上超越先前SOTA方法,展示出强大的三维场景理解和交互能力
应用场景涵盖家庭助理、智能导览、仓储物流等,可执行物品寻找、家居整理等复杂任务
MindLoongGPT/龙跃 (国家地方共建人形机器人创新中心)
全球首款生成式人形机器人运动大模型,实现"自然语言驱动"的高保真动作生成
突破传统运动控制范式,用户只需说出"挥手致意"或上传参考视频,模型即可自动解析语义生成连贯动作
已应用于青龙机器人,支持丰富的全身动作生成,同时作为仿真平台的数据生成引擎
Multi-SpatialMLLM (Meta)
专注于多帧空间理解,在MultiSPA数据集(2700万样本)上训练,支持多种引用方式和输出格式
在BLINK基准测试中多视图推理准确率接近90%,超越多个专有模型,展示出强大的跨数据集泛化能力
可作为机器人学习的"多帧奖励标注器",通过分析连续帧中物体移动情况评估任务完成度
Aether (上海AI Lab)
开源生成式世界模型,完全基于合成数据训练但具备真实世界零样本泛化能力
三大核心能力:4D动态重建、动作条件视频预测、目标导向视觉规划,支持机器人导航、自动驾驶等场景
采用扩散模型与多模态融合技术,将深度视频和相机轨迹编码为统一表示
CoELA (马萨诸塞大学)
模块化设计的合作型具身智能体,由感知、记忆、沟通、决策和执行五个模块组成
特别强调多智能体协作能力,通过LLM的丰富常识和自由形式语言生成能力实现高效沟通
在分散环境中展示出卓越的长期多任务协作能力,为人-机-环境协同提供新范式
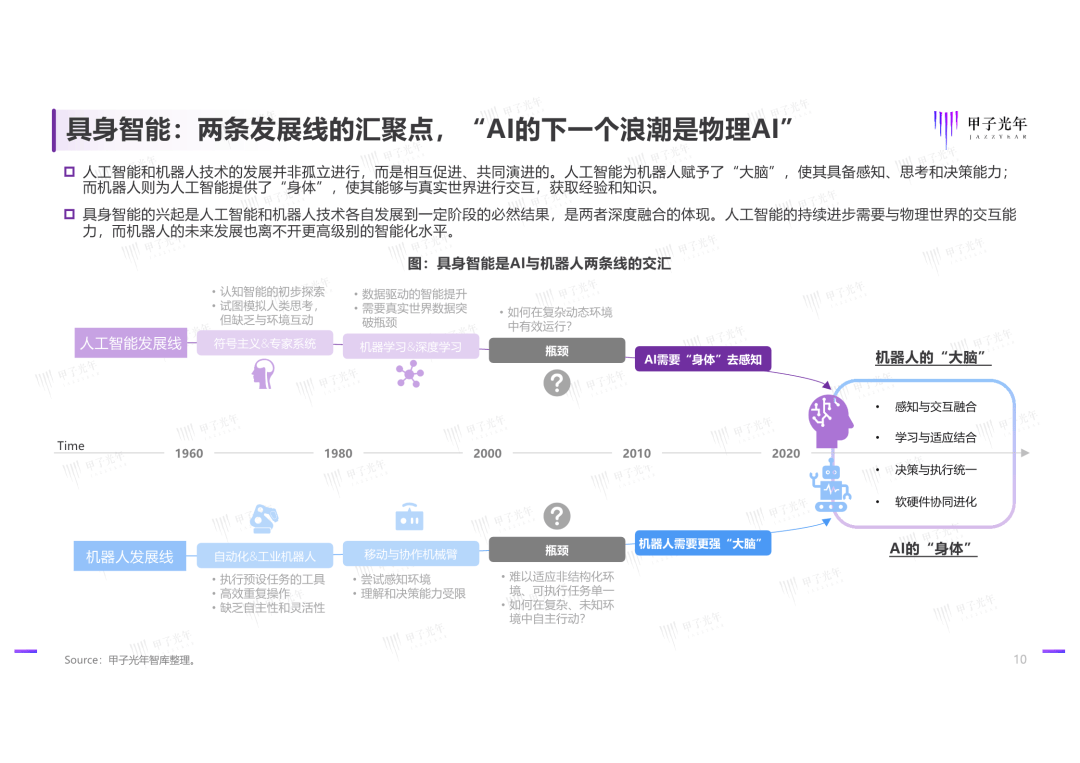
应用场景与实践
具身智能多模态大模型正在多个领域展现出变革性应用潜力:
工业与人形机器人
工业场景:LEO模型可用于仓储物流中的物品整理搬运,MindLoongGPT优化人形机器人运动控制
家庭服务:作为家庭助理完成打扫、整理、简单厨房任务,或根据用户喜好调整家居布局
国地中心联合企业建设"麒麟训练场",部署超100台异构人形机器人,加速数据采集和技能开发
医疗健康
临床全周期:术前智能诊断、术中机器人辅助手术、术后康复训练和健康监测
护理陪伴:社交机器人(如NAO、QTrobot)辅助自闭症儿童治疗,外骨骼设备(如ReWalk)支持脊髓损伤患者康复
设施运营:药品配送机器人、消毒机器人提升医院运营效率,特别是在疫情期间减少交叉感染
自动驾驶与智能交通
虚拟现实与数字孪生
特殊环境作业
发展挑战与未来方向
尽管前景广阔,具身智能多模态大模型仍面临多重挑战:
数据瓶颈
具身智能需要PB级高质量多模态数据,远超自动驾驶等领域的需求
数据多样性(真机数据、合成数据、互联网数据)与质量控制是关键难题
解决方案:建设大型训练场(如麒麟训练场)、开发高效数据生成工具(如MindLoongGPT)
模型适应性
计算与实时性
多智能体协作
安全与伦理
物理世界交互带来的安全风险需系统化解决框架
医疗等敏感领域的行为可解释性和责任归属问题
未来发展方向包括:
规模扩展:更大模型、更多数据,如国地中心计划将操作精度从70-80%提升至90%,达到"ChatGPT-3时刻"
多模态融合:融入触觉、力觉等更多感知模态,构建更全面的世界模型
持续学习:开发适应动态环境的在线学习机制,避免灾难性遗忘
标准化生态:推动人形机器人产业标准互认,形成开源开放的开发范式
具身智能多模态大模型正引领AI从"数字智能"迈向"物理智能",其发展将深刻改变人机交互方式和社会生产模式。随着技术突破和生态完善,我们有望在未来几年见证其"GPT时刻"的到来。